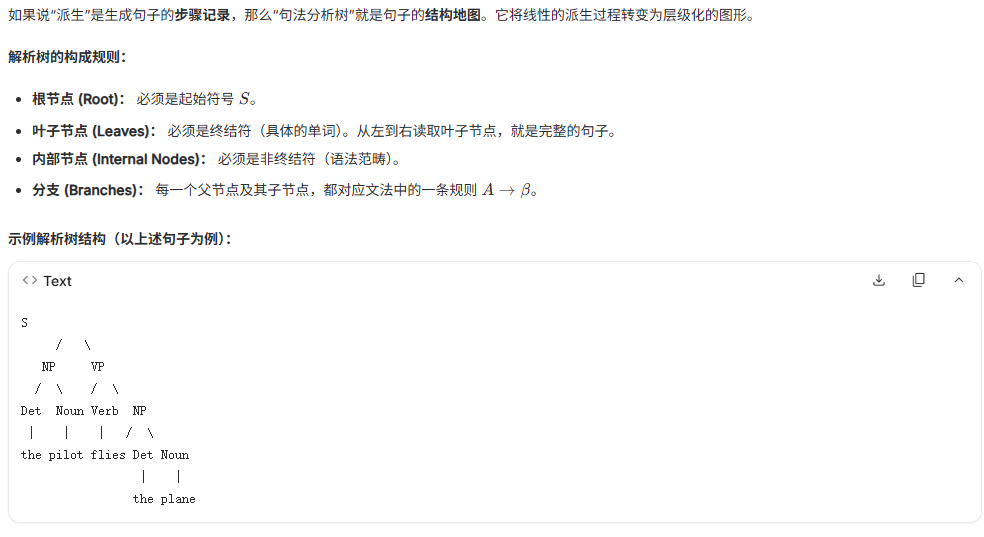
好的,我理解了。你需要一份完整涵盖整个 PDF 内容(从语言学层级到 CYK 算法再到现代视角),并且严格遵守你给出的层级结构(Part I, Part II...)以及使用 $$ 包裹 LaTeX 公式的笔记。
以下是为你重头整理的详细笔记:
Lecture 6: Introduction to NLP: Grammar, Syntax, and Context-Free Grammars
Part I: Linguistic Hierarchy & Syntax Basics
-
Levels of Languages (语言层级):
语言处理存在一个从声音到隐含意义的垂直层级。- Phonology (语音学): 研究所有声音 (All sounds)。
- Morphology (形态学): 研究单词的内部结构。例如:unhappiness 拆解为 un-happi-ness。
- Syntax (句法学): 研究单词如何组织成短语和句子(Organizing words)。
- Semantics (语义学): 研究字面含义(Literal meaning)。
- Pragmatics (语用学): 研究隐含意义,如隐喻、讽刺、幽默和沉默。
-
Syntax Definition (句法定义):
句法是定义单词如何组织成更大单元的规则。- Legal vs. Illegal: 规则区分了语言中的合法与非法句子。
- Fluency: 衡量对句法规则的熟悉程度。婴儿通过习得(Acquisition)掌握,二语学习者通过规则(Rules)显式学习。
-
Shallow vs. Deep Syntax (浅层与深层句法):
- Shallow Syntax: 关注语言的局部结构。
- Examples: the 后面接名词;主谓一致(he drinks vs. they drink)。
- Modeling: n-grams and HMM 是马尔可夫模型(Markovian),仅利用近距离历史,无法处理长程依赖。
- Deep Syntax: 关注全局和长程依赖。
- Example: "The books that I bought yesterday are expensive."
- Analysis: are 取决于复数名词 books,两者之间的距离超出了 n-gram 处理范围。
- Shallow Syntax: 关注语言的局部结构。
-
Constituent (语法成分):
作为一个单一语法单元行动的一组词。- Property 1: 可以在句中不同位置出现而不改变语义(Position flexibility)。
- Property 2: 不能在维持语义的情况下被进一步拆解(Indivisibility)。
Part II: Context-Free Grammar (CFG)
-
Formal Definition (形式化定义):
一个上下文无关文法由四个元素组成:: 非终结符集合(Non-terminal symbols),如 NP, VP。 : 终结符集合(Terminal symbols),即具体的单词。 : 规则/产生式集合,形式为 ,其中 。 : 起始符号, 。
-
核心短语范畴 (Phrasal Categories),这些符号代表由多个词组成的短语单位:
(Noun Phrase): 名词短语。句子的主体,通常指代人、事、物。例如:a flight(一个航班), the big blue bus(那辆蓝色大巴士)。 (Verb Phrase): 动词短语。描述动作或状态。例如:prefer a morning flight(倾向于早班机), disappear(消失)。 (Prepositional Phrase): 介词短语。由介词开头,表示地点、时间、方式等。例如:from Atlanta(来自亚特兰大), in the morning(在早上)。 (Adjective Phrase): 形容词短语。以形容词为核心。例如:least expensive(最便宜的)。 或 (Noun): 名词。表示人、地点、事物或概念的词。这是 和 的核心。 或 (Verb): 动词。 表示动作、事件或状态的词。这是 的核心。 或 (Adjective): 形容词。用来修饰名词,描述其属性。它是 的核心。 或 (Adverb): 副词。 用来修饰动词、形容词或其他副词。 -
核心句子与词类范畴 (Clausal & Word Categories)
(Sentence): 句子。文法的最高层级,通常由 和 组成。 (Auxiliary): 助动词。协助主要动词构成时态、语态或疑问。例如:do, does, can, will, have。在是非问句(Yes-no Questions)中常用到它(如:Do any of these flights...)。 (Determiner): 限定词。放在名词前限定其范围。例如:a, an, the, this, that。 (名词性成分): 介于名词和名词短语之间的成分。它比单个名词信息更多,但还没加上限定词。例如:morning flight 是一个 ,加上 a 之后变成 (a morning flight)。 : 疑问名词短语。引导疑问句的特殊名词短语,通常包含 who, what, which 等。例如:What airlines。 或 (Preposition): 介词。 (介词短语) 的核心词,通常放在名词短语之前,表示位置、时间或逻辑关系。 或 (Conjunction): 连词。用于连接两个相同的语法成分(如连接两个 或两个 )。这是造成并列歧义的主要原因。 或 (Pronoun): 代词。** 用来替代名词短语的词。在解析树中,它通常直接作为一个 。 或 (Cardinal Number): 基数词。定义: 表示数量的词。 (Ordinal Number): 序数词。表示顺序的词。 (Quantifier): 数量词。比限定词更具体地表示数量(不确定数量)。 或 (Complementizer Phrase): 补语从句/关系从句。定义: 由 that 或 which 等词引导的从句。它通常作为一个修饰语嵌套在 或 中。 (Wh-Adverb): 疑问副词。定义: 引导疑问句的副词,询问时间、地点或原因。 -
Sentence Structures (句子结构规则):
- Declarative (陈述句): $$S \rightarrow NP\ VP$$
- Imperative (祈使句): $$S \rightarrow VP$$
- Yes-no Questions (是非问句): $$S \rightarrow Aux\ NP\ VP$$
- Wh-structures: $$S \rightarrow Wh-NP\ VP$$ 或 $$S \rightarrow Wh-NP\ Aux\ NP\ VP\ PP$$
-
Noun Phrase & Nominals (名词短语与名词性成分):
- NP Rule: $$NP \rightarrow (Det) (Card) (Ord) (Quant) (AP) Nominal$$ (括号内为可选成分)。
- Recursion (递归): 通过限定词规则 $$Det \rightarrow NP's$$ 可以实现深层嵌套,如 "Denver’s mayor’s mother’s canceled flight"。
- Nominal Forms:
-
-
Verb Phrase (VP):
(disappear) (prefer a morning flight) (含有句法补足语 Sentential complement)
-
Data Source: Penn Treebank 是常用的解析树标注语料库,用于派生 CFG 或训练解析器。
Part III: Syntactic Parsing & Ambiguity
-
The Goal of Parsing:
给定一个 CFG,为句子分配有效的解析树。即寻找根节点为、叶子节点为句子单词的树。 -
Search Strategies (搜索策略):
- Top-down Search (自顶向下): 从起始符
开始向下扩展,直到匹配单词。 - Bottom-up Search (自底向上): 从单词开始向上构建非终结符,直到到达
。 - Common Issue: 存在大量的重复子问题。解析树的某些部分(如特定的 NP)会被反复构建,即使最终会导致解析失败(
)。
- Top-down Search (自顶向下): 从起始符
-
Parsing Ambiguity (分析歧义性):
- Attachment Ambiguity (附件歧义): 修饰成分的归属不明确。
- Example: "I saw the Grand Canyon flying to New York." (谁在飞?我还是大峡谷?)
- Coordination Ambiguity (并列歧义): 连词连接的范围不明确。
- Example: "old men and women" (是“老的老头和老太太”,还是“老头和所有女人”?)
- Example: "old men and women" (是“老的老头和老太太”,还是“老头和所有女人”?)
- Attachment Ambiguity (附件歧义): 修饰成分的归属不明确。
Part IV: CYK Algorithm & CNF
-
Motivation (动机):
利用动态规划(Dynamic Programming)缓存子问题的解,避免重复解析。 -
Chomsky Normal Form (CNF):
CYK 算法要求文法必须转换为 CNF 形式:- Conversion Algorithm (转换算法):
- 处理混合右侧:$$A \rightarrow Bc \implies A \rightarrow BC, C \rightarrow c$$
- 消除单位产生式:$$A \rightarrow B$$
- 处理长右侧:$$A \rightarrow BCD \implies A \rightarrow XD, X \rightarrow BC$$
-
-
CYK Algorithm Mechanics (算法原理):
- 使用一个
的矩阵,其中 是单词数。 - 单元格
包含所有能生成从位置 到 的成分的非终结符。 - Logic: 由于满足 CNF,每个成分
都可以被切分为两部分: 和 ,其中 。 - Formula: 如果
且 ,且存在规则 ,则将 加入 。
- 使用一个
Part V: The Bitter Lesson
- Core Concept (Rich Sutton):
在 NLP 发展史上,关于“构建人类知识(如句法规则)”与“利用大规模计算发现知识”一直存在争论。 - Key Argument:
从长远来看,利用大规模数据和可扩展计算的方法()总是优于硬编码人类知识的方法。 - Shift in Paradigm:
- Past: 专注于复杂的句法解析步骤(
)。 - Present (LLM): 通过下一标记预测(
),模型可以直接学习语言规律。
- Past: 专注于复杂的句法解析步骤(
- Conclusion:
虽然在 LLM 时代显式构建语法树可能显得不再必要,但学习这些概念对于理解语言结构和建立 NLP 直觉仍然至关重要。
好的,这是根据 PDF 后半部分(Page 15 - Page 29)整理的后续笔记。这部分重点讲解了句法分析的搜索策略、歧义性以及解决效率问题的核心算法——CYK 算法。
Part VI: Syntactic Parsing & Search Strategies
-
Goal (目标):
给定一个 CFG 和一个句子,为该句子分配有效的解析树(Parsing trees)。- Root constraint: 树的根节点必须是起始符号
。 - Leaf constraint: 树的叶子节点必须是句子中的单词。
- Process: 本质上是 CFG 生成句子过程的逆过程。
- Root constraint: 树的根节点必须是起始符号
-
Search Strategies (搜索策略):
句法分析本质上是一个在搜索空间中寻找合法树的过程。- Top-down Search (自顶向下搜索):
- Method: 从根节点
开始,根据规则 逐步展开非终结符。 - Pruning: 当展开的叶子无法匹配输入句子中的单词时进行剪枝。
- Stop: 当生成的叶子序列与输入句子完全匹配时停止。
- Issue: 可能会盲目地构建很多最终无法匹配输入单词的树结构。
- Method: 从根节点
- Bottom-up Search (自底向上搜索):
- Method: 从叶子节点(输入单词)开始,利用规则右侧匹配,逐步归约为非终结符(如
)。 - Pruning: 当生成的结构无法进一步组合或匹配任何规则右侧时剪枝。
- Stop: 当最终归约为根节点
时停止。 - Issue: 可能会构建很多无法最终连接到根节点
的孤立子树。
- Method: 从叶子节点(输入单词)开始,利用规则右侧匹配,逐步归约为非终结符(如
- Top-down Search (自顶向下搜索):
-
The Problem: Repeated Subproblems (重复子问题):
无论是自顶向下还是自底向上,单纯的搜索算法效率很低。- Reason: 在搜索树的不同分支中,相同的子串(如 "that flight")会被反复解析,即使之前的尝试已经证明它在某种组合下是死胡同(
)。 - Solution: 需要引入动态规划 (Dynamic Programming) 思想,缓存子问题的解。
- Reason: 在搜索树的不同分支中,相同的子串(如 "that flight")会被反复解析,即使之前的尝试已经证明它在某种组合下是死胡同(
Part VII: Structural Ambiguity (结构歧义)
同一个句子在句法上可能有多种合法的解析树,导致语义不同。这是 NLP 解析的难点。
-
Attachment Ambiguity (附件歧义):
修饰性短语(如介词短语 PP 或分词短语)依附的对象不明确。- Example: "I saw the Grand Canyon flying to New York."
- Case 1:
(saw) (flying...)。意味着“我”在飞往纽约时看到了峡谷。 - Case 2:
(Grand Canyon) (flying...)。意味着“大峡谷”在飞往纽约(虽然语义滑稽,但在句法上是合法的)。
- Case 1:
- Example: "I saw the Grand Canyon flying to New York."
-
Coordination Ambiguity (并列歧义):
连词(如 and)连接的范围不明确。- Example: "old men and women"
- Case 1:
。 仅修饰 。 - Case 2:
。 修饰整个 ,即老人和老妇人。
- Case 1:
- Example: "old men and women"
Part VIII: CYK Algorithm (Dynamic Programming)
CYK (Cocke-Younger-Kasami) 算法是解决 CFG 解析效率问题的标准动态规划算法。
-
Core Idea (核心思想):
- Overlapping Sub-problems: 重复利用子问题的解(即解析过的子串不需要重新解析)。
- Optimal Substructure: 一个大的成分(如
)是由更小的成分(如 )成功组合而成的。如果子成分解析错误,大成分也不可能正确。
-
Prerequisite: Chomsky Normal Form (CNF, 乔姆斯基范式):
CYK 算法要求 CFG 必须转化为 CNF 形式,以便于构建标准化的二叉树结构。- CNF Rules: 规则只能是以下两种形式之一:
(右侧严格为两个非终结符) (右侧严格为一个终结符)
- Conversion (转化): 任何 CFG 都可以转化为 CNF 而不损失表达能力。
- 混合规则转化:
- 长规则转化:
- 混合规则转化:
- CNF Rules: 规则只能是以下两种形式之一:
-
The Algorithm (算法流程):
假设句子有个单词。 - Data Structure: 构建一个
的三角矩阵(或表)。 - 单元格
存储的是:能生成句子中从位置 到 的子串的所有非终结符集合。
- 单元格
- Initialization (底层):
- 对于每个单词
,如果存在规则 ,将 填入 。这是矩阵的对角线。
- 对于每个单词
- Recursion (填表):
- 对于跨度
从 2 到 (子串长度): - 对于起始位置
从 0 到 : - 设结束位置
。 - 尝试所有可能的分割点
( )。 - 核心逻辑: 如果
且 ,并且文法中存在规则 ,则将 加入 。
- 设结束位置
- 对于起始位置
- 对于跨度
- Termination (终止):
- 检查右上角单元格
。如果其中包含起始符号 ,则解析成功。
- 检查右上角单元格
- Data Structure: 构建一个
-
Efficiency:
通过缓存,避免了重复解析相同的子串,将指数级的搜索复杂度降低到了多项式级别(通常是 )。