1. 基本操作 (Basic Operations)
1.0 工具 (Tools)
这些是 Python 内置的实用函数,对于探索库和对象非常有用:
dir(package_or_module): 列出指定包或模块中可用的所有名称(变量、函数、类等)。- 例如:
dir(torch)会显示torch命名空间下的所有内容。 - 例如:
dir(torch.optim)会显示torch.optim模块下的所有内容。
- 例如:
dir(object): 列出对象的所有属性和方法。- 如果列表主要包含
__xxx__形式的名称(称为 "dunder" 或 "magic" methods/attributes),这通常表明该对象是一个类的实例、一个类本身,或者一个内置类型/函数。例如,dir(my_list_object)或dir(str).
- 如果列表主要包含
help(item): 显示关于item(可以是模块、类、函数、方法或变量)的帮助文档/文档字符串 (docstring)。- 例如:
help(torch.nn.Linear)会告诉你如何使用Linear层。 - 例如:
help(my_dataset_instance)会显示MyDataset类的文档字符串(如果定义了的话)。
- 例如:
1.1 加载数据 (Load Data)
1.1.1 基本函数 (Basic Function)
PyTorch 提供了两个核心工具来简化和优化数据加载流程:torch.utils.data.Dataset 和 torch.utils.data.DataLoader。
-
Dataset:- 是一个抽象类,代表一个数据集。
- 你需要继承它并重写
__len__(返回数据集大小) 和__getitem__(支持从0到len(self)-1的整数索引,返回一个数据样本)。 - 它负责存储样本及其对应的标签(或其他目标值),并提供按索引访问单个样本的能力。
-
DataLoader:- 是一个迭代器,它将
Dataset包装起来。 - 功能:
- 批量处理 (Batching): 将数据组织成小批量 (mini-batches)。
- 打乱数据 (Shuffling): 在每个 epoch 开始时打乱数据顺序,有助于模型训练。
- 并行加载 (Multiprocessing): 使用多个子进程并行加载数据,避免数据加载成为训练瓶颈。
- 自动整理 (Collation): 将从
Dataset获取的单个样本聚合成批次。
- 是一个迭代器,它将
基本使用流程:
-
定义你自己的
Dataset类:from torch.utils.data import Dataset, DataLoader import torch # 假设你的数据会转换为 PyTorch 张量 # import numpy as np # 如果你从 numpy 数组加载 # import pandas as pd # 如果你从 csv 加载 class MyDataset(Dataset): def __init__(self, data_source, transform=None): # 1. 初始化阶段:通常在这里加载和预处理所有数据 # data_source 可以是文件路径、数据列表、或其他数据源指示符 # 例如: # - self.data = pd.read_csv(data_source).values # - self.image_paths = glob.glob(os.path.join(data_source, '*.jpg')) # - self.raw_data = data_source # 如果数据已经加载好传入 self.data = ... # 示例:假设 self.data 存储了所有样本 self.labels = ... # 示例:假设 self.labels 存储了所有标签 # self.n_samples = len(self.data) # 如果数据是列表或类似结构 self.transform = transform # 可选的数据转换/增强操作 def __getitem__(self, index): # 2. 按索引获取单个样本 # 必须返回一个样本,通常是 (features, label) 的元组 sample = self.data[index] label = self.labels[index] if self.transform: sample = self.transform(sample) # 应用转换 # 确保返回的是 PyTorch 张量 (通常在 Dataset,DataLoader 的 collate_fn 中处理) # return torch.tensor(sample, dtype=torch.float32), torch.tensor(label, dtype=torch.long) return sample, label def __len__(self): # 3. 返回数据集的总样本数 return len(self.data) # 或 self.n_samples -
实例化
Dataset和DataLoader:# 假设 'my_data_file.csv' 是你的数据文件 dataset = MyDataset(data_source='my_data_file.csv') # 或者其他数据源 # 对于训练数据,通常启用 shuffle train_dataloader = DataLoader(dataset=dataset, batch_size=64, # 每个批次包含的样本数 shuffle=True, # 在每个 epoch 开始时打乱数据 num_workers=2) # 使用多少子进程加载数据 (0表示在主进程中加载) # 对于测试/验证数据,通常不打乱 # test_dataset = MyDataset(data_source='my_test_data.csv') # test_dataloader = DataLoader(dataset=test_dataset, # batch_size=64, # shuffle=False, # num_workers=2)注意
shuffle参数:- 训练 (Training) 时:
shuffle=True是推荐的,有助于模型泛化,防止模型按特定顺序学习数据。 - 测试 (Testing) / 验证 (Validation) 时:
shuffle=False是推荐的,以确保每次评估的顺序一致,便于比较和复现结果。
- 训练 (Training) 时:
示例 :
-
- 假设有一个
wine.csv文件,前N-1列是特征,最后一列是标签。
- 假设有一个
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
class WineDataset(Dataset):
def __init__(self, filepath, transform=None):
# 加载数据: 使用 numpy 加载 CSV 文件,跳过标题行,指定分隔符
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32, skiprows=1)
self.n_samples = xy.shape[0]
# 将数据分为特征 (X) 和标签 (y)
# 这里假设最后一列是标签,其余是特征
self.x_data = torch.from_numpy(xy[:, :-1]) # 所有行, 除了最后一列
self.y_data = torch.from_numpy(xy[:, [-1]]) # 所有行, 只有最后一列
self.transform = transform
def __getitem__(self, index):
sample = self.x_data[index]
label = self.y_data[index]
if self.transform:
# 注意:这里的 transform 通常用于图像增强等
# 对于表格数据,转换可能在 __init__ 中完成,或有特定于表格的转换
sample = self.transform(sample)
return sample, label
def __len__(self):
return self.n_samples
# 使用
# dataset = WineDataset('wine.csv')
# dataloader = DataLoader(dataset=dataset, batch_size=4, shuffle=True)
# # 迭代 DataLoader 获取批次数据
# data_iter = iter(dataloader)
# features, labels = next(data_iter)
# print(features)
# print(labels)
-
- label 与文件夹名称相同
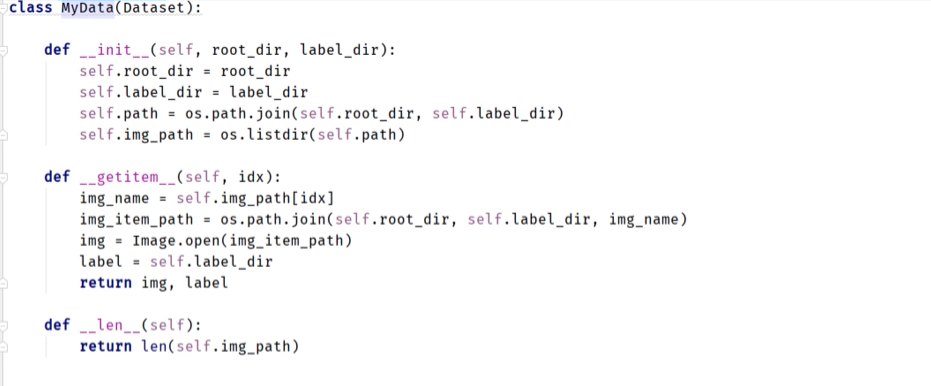
- label 与文件夹名称相同
-
- label 描述在文本文件里
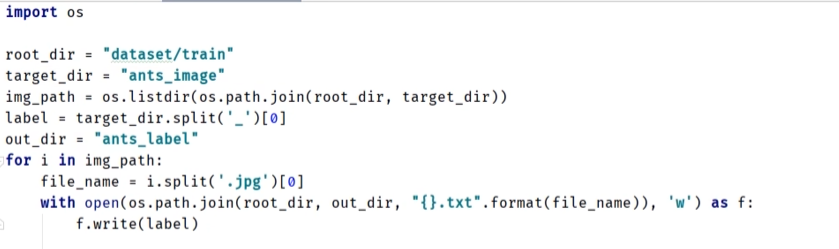
- label 描述在文本文件里
1.1.2 数据集操作 (Dataset Operations)
- 数据集串联 (Concatenation):
PyTorch 的Dataset对象可以直接使用+操作符进行拼接,这实际上是使用了torch.utils.data.ConcatDataset。
示例:dataset1 = MyDataset(source_A) dataset2 = MyDataset(source_B) # 合并两个数据集 combined_dataset = dataset1 + dataset2 # 或者显式使用 ConcatDataset # from torch.utils.data import ConcatDataset # combined_dataset = ConcatDataset([dataset1, dataset2]) print(len(dataset1)) print(len(dataset2)) print(len(combined_dataset)) # 输出: len(dataset1) + len(dataset2) # combined_dataloader 可以基于 combined_dataset 创建 combined_dataloader = DataLoader(dataset=combined_dataset, batch_size=32, shuffle=True)
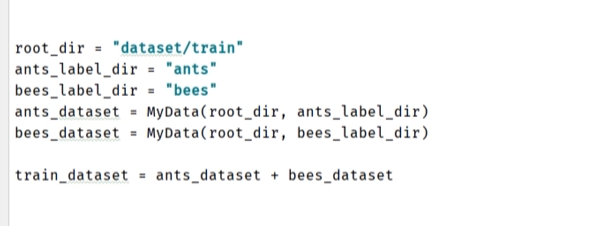
这在需要合并来自不同来源的训练数据,或者合并训练集和部分验证集进行训练时非常有用。
1.3 TensorBoard
TensorBoard 是一个强大的可视化工具,最初为 TensorFlow 开发,但 PyTorch 通过 torch.utils.tensorboard 模块提供了出色的支持。它能帮助你可视化模型图、跟踪训练指标(如损失和准确率)、查看权重和梯度的分布、展示图像等,对于调试、理解和优化神经网络至关重要。
1.3.1 介绍 (Introduction)
- 目的 (Purpose): TensorBoard 提供了一系列可视化工具,使你能够:
- 实时跟踪和可视化训练过程中的指标(例如损失函数值、准确率)。
- 可视化模型的计算图结构。
- 查看模型权重、偏置或梯度的直方图,了解它们的分布和变化。
- 展示输入的图像、生成的图像、特征图等。
- 分析词嵌入或图像特征嵌入在高维空间中的分布(例如使用 t-SNE 或 PCA 降维投影)。
- 工作原理 (How it works):
- 在 PyTorch 脚本中,你使用
SummaryWriter对象将训练过程中的各种数据(标量、图像、直方图等)写入到指定的日志目录 (logdir)。 - 然后,在你的终端(命令行)中启动 TensorBoard 服务,并让它指向这个日志目录。
- 最后,通过浏览器访问 TensorBoard 提供的网址(通常是
http://localhost:6006)来查看和分析这些可视化数据。
- 在 PyTorch 脚本中,你使用
1.3.2 基本操作 (Basic Operations)
首先,你需要导入 SummaryWriter 并实例化它。
from torch.utils.tensorboard import SummaryWriter
import torch
import torchvision # For image examples
import numpy as np # For generating example data
初始化 SummaryWriter
SummaryWriter 是将数据写入 TensorBoard 事件文件的核心类。
# writer = SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
SummaryWriter 构造函数参数详解:
log_dir (str, optional): 指定事件文件存储的目录。- 如果为
None(默认),日志将保存在runs/CURRENT_DATETIME_HOSTNAME格式的目录中。 - 如果提供路径,例如
'runs/my_experiment',则日志将保存在该目录下。TensorBoard 启动时需要指向这个log_dir或其父目录。
- 如果为
comment (str, optional): 一个可选的后缀,会附加到默认log_dir的末尾(如果log_dir未指定)。例如,如果comment='_my_model',则默认目录可能变为runs/CURRENT_DATETIME_HOSTNAME_my_model。这有助于区分在同一时间戳附近生成的不同运行。purge_step (int, optional): TensorBoard 可能因意外关闭(如Ctrl+C)而留下未完成的事件文件。当下一次使用相同的log_dir启动SummaryWriter时,如果purge_step被设置,它会清除在该步骤(global_step)之后的所有事件。这有助于清理损坏的运行。max_queue (int, optional): 在将事件异步写入磁盘之前,内存中事件队列的最大大小。默认为 10。flush_secs (int, optional): 将队列中的事件刷新(写入)到磁盘的频率(以秒为单位)。默认为 120 秒(2分钟)。filename_suffix (str, optional): 可选的文件名后缀,会附加到事件文件的名称上。默认为空。
示例实例化:
# 推荐做法:为每次实验指定一个清晰的日志目录
writer = SummaryWriter('runs/mnist_experiment_1')
# 或者使用默认目录
# writer_default = SummaryWriter()
现在,让我们看看如何使用 writer 对象记录不同类型的数据。
1. 记录标量 (Logging Scalars)
用于跟踪单个数值随时间(或训练步骤)的变化,如损失、准确率、学习率等。
writer.add_scalar(tag, scalar_value, global_step=None, walltime=None)
tag (str): 数据标识符,例如'Loss/train'或'Accuracy/validation'。斜杠/用于在 TensorBoard UI 中创建层级结构。scalar_value (float or int): 要记录的标量值。global_step (int, optional): 记录该数据点时对应的全局步骤,通常是迭代次数或 epoch 数。这将是图表中的 x 轴。walltime (float, optional): 事件发生的时间戳,默认为time.time()。一般不需要手动设置。
print("Logging scalars...")
for n_iter in range(100):
loss = 0.99**n_iter # 模拟损失下降
accuracy = 1.0 - loss * 0.8
writer.add_scalar('Training/Loss', loss, n_iter)
writer.add_scalar('Training/Accuracy', accuracy, n_iter)
# 如果想在同一张图上比较多个标量,可以使用 add_scalars
# writer.add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
# - main_tag (str): 这组标量图的主标题。
# - tag_scalar_dict (dict): 一个字典,键是子标签,值是对应的标量值。
print("Logging grouped scalars...")
for n_iter in range(50):
writer.add_scalars('Loss_Variations', {
'loss_A': np.random.random() + n_iter/50.0,
'loss_B': np.random.random() * 0.5 + n_iter/50.0
}, n_iter)
2. 记录直方图 (Logging Histograms)
用于可视化张量(如模型权重、偏置、梯度或激活值)的分布情况。
writer.add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
tag (str): 直方图的标识符。values (torch.Tensor, numpy.ndarray): 包含要绘制直方图的数据的张量。global_step (int, optional): 全局步骤。bins (str, optional): 生成直方图的分箱策略。'tensorflow'(默认),'auto','fd','doane','scott','stone','rice','sturges', 或'sqrt'。
print("Logging histograms...")
# 模拟不同 epoch 的权重变化
for epoch in range(10):
# 假设这是模型某一层权重的快照
dummy_weights = torch.randn(1000) * (epoch + 1) * 0.1 + epoch
writer.add_histogram('Model_Layer1/weights', dummy_weights, epoch)
dummy_biases = torch.rand(100) - 0.5 + epoch * 0.1
writer.add_histogram('Model_Layer1/biases', dummy_biases, epoch)
3. 记录图像 (Logging Images)
用于在 TensorBoard 中显示单个图像。
writer.add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
tag (str): 图像的标识符。img_tensor (torch.Tensor or numpy.ndarray): 图像数据。- 可以是 3D 张量 (CHW 或 HWC) 或 2D 张量 (HW - 灰度图)。
- CHW: Channel, Height, Width (PyTorch 默认)。
- HWC: Height, Width, Channel (Matplotlib, PIL 默认)。
- HW: Height, Width.
global_step (int, optional): 全局步骤。dataformats (str, optional): 指定img_tensor的格式,如'CHW','HWC','HW'。默认为'CHW'。张量的值通常应归一化到[0, 1](浮点数) 或[0, 255](整数)。
print("Logging a single image...")
# 创建一个随机图像作为示例
# CHW format: 3 channels (RGB), 64 height, 128 width
random_img_chw = torch.rand(3, 64, 128)
writer.add_image('Sample_Images/Random_CHW', random_img_chw, 0)
# HWC format: 32 height, 32 width, 3 channels (RGB)
random_img_hwc = torch.rand(32, 32, 3)
writer.add_image('Sample_Images/Random_HWC', random_img_hwc, 1, dataformats='HWC')
# Grayscale image (HW format)
random_img_hw = torch.rand(40, 40)
writer.add_image('Sample_Images/Random_Grayscale_HW', random_img_hw, 2, dataformats='HW')
4. 记录一批图像 (Logging a Batch of Images)
用于将一批图像作为一个网格(grid)显示。
writer.add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')
tag (str): 图像批次的标识符。img_tensor (torch.Tensor or numpy.ndarray): 包含一批图像的张量。- 通常是 4D 张量。
global_step (int, optional): 全局步骤。dataformats (str, optional): 指定img_tensor的格式,如'NCHW'(Batch, Channel, Height, Width - PyTorch 默认) 或'NHWC'。
print("Logging a batch of images...")
# 创建一个随机图像批次 (4 images, 3 channels, 32x32)
random_batch_nchw = torch.rand(4, 3, 32, 32)
writer.add_images('Sample_Images_Batch/Random_Batch_NCHW', random_batch_nchw, 0)
# 也可以使用 torchvision.utils.make_grid 先手动创建网格,然后用 add_image
img_grid = torchvision.utils.make_grid(random_batch_nchw)
writer.add_image('Sample_Images_Batch/Random_Batch_Grid_Manual', img_grid, 1)
5. 记录模型图 (Logging Model Graph)
可视化模型的结构和操作流程。
writer.add_graph(model, input_to_model=None, verbose=False, use_strict_trace=True)
model (torch.nn.Module): 你要可视化的 PyTorch 模型。input_to_model (torch.Tensor or tuple of torch.Tensor, optional): 一个符合模型forward方法输入的示例张量或张量元组。模型会用这个输入进行一次追踪(trace)以生成图。verbose (bool, optional): 是否打印图的调试信息。use_strict_trace (bool, optional): 是否使用严格的追踪模式。对于某些动态图模型,设置为False可能有助于生成图,但可能不完全准确。
print("Logging model graph...")
class SimpleNet(torch.nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.relu1 = torch.nn.ReLU()
self.pool1 = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(10 * 12 * 12, 50) # Assuming input 1x28x28 for MNIST
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = x.view(-1, 10 * 12 * 12)
x = self.fc(x)
return x
dummy_model = SimpleNet()
# 示例输入:batch_size=1, channels=1, height=28, width=28 (e.g., MNIST)
dummy_input = torch.randn(1, 1, 28, 28)
try:
writer.add_graph(dummy_model, dummy_input)
except Exception as e:
print(f"Could not add graph (common issue with some PyTorch/ONNX versions, or complex inputs/control flow): {e}")
print("Graph logging can be tricky. Ensure 'input_to_model' matches model's forward pass expectations exactly.")
注意: add_graph 对于包含复杂控制流(例如依赖于输入的 if 语句)的模型可能无法完美工作,因为它依赖于 JIT 追踪。
6. 记录文本 (Logging Text)
在 TensorBoard 中显示文本信息,如超参数配置、笔记等。
writer.add_text(tag, text_string, global_step=None, walltime=None)
tag (str): 文本的标识符。text_string (str): 要显示的文本内容。支持 Markdown 格式。global_step (int, optional): 全局步骤。
print("Logging text...")
hyperparameters_info = """
### Experiment Configuration
- **Learning Rate**: 0.001
- **Batch Size**: 64
- **Optimizer**: Adam
- **Epochs**: 50
"""
writer.add_text('Experiment_Setup/Hyperparameters', hyperparameters_info, 0)
writer.add_text('Notes', "This run uses a new data augmentation technique.", 0)
7. 记录超参数 (Logging Hyperparameters - hparams)
这是一个更结构化的方式来记录实验的超参数组合及其对应的最终性能指标,非常适合进行超参数调优和比较。
writer.add_hparams(hparam_dict, metric_dict, hparam_domain_discrete=None, run_name=None)
hparam_dict (dict): 包含超参数名称和它们的值的字典,例如{'lr': 0.1, 'optimizer': 'Adam'}。metric_dict (dict): 包含在这些超参数下达到的最终指标值的字典,例如{'hparam/accuracy': 0.95, 'hparam/loss': 0.12}。TensorBoard 的 HParams 插件要求指标名称以hparam/开头,或者你可以不加前缀,它会自动处理。hparam_domain_discrete (dict, optional): 一个字典,键是超参数名称,值是该超参数所有可能取值的列表。例如{'optimizer': ['Adam', 'SGD']}。这有助于 TensorBoard 知道超参数的范围。run_name (str, optional): 此特定超参数运行的名称。如果提供,它会用于创建此运行的子目录。
print("Logging hyperparameters...")
# 模拟两次不同的超参数运行
hparams_run1 = {'lr': 0.01, 'batch_size': 32, 'optimizer': 'SGD'}
metrics_run1 = {'hparam/accuracy': 0.75, 'hparam/loss': 0.5}
hparams_run2 = {'lr': 0.001, 'batch_size': 64, 'optimizer': 'Adam'}
metrics_run2 = {'hparam/accuracy': 0.88, 'hparam/loss': 0.25}
# 注意:当使用 add_hparams 时,通常会为每个超参数组合创建一个新的 SummaryWriter
# 或者,如 PyTorch 官方教程所示,在单个 writer 的不同子目录中记录。
# 这里为了简化,我们尝试在同一个 writer 上记录,但这可能不是最佳实践。
# 更好的方法是为每个 hparam run 创建一个单独的 writer 实例,并给不同的 log_dir
# e.g., writer_hparam_run1 = SummaryWriter('runs/hparam_exp/run1')
# writer_hparam_run1.add_hparams(hparams_run1, metrics_run1)
# writer_hparam_run1.close()
try:
# 记录第一个运行
# 为了让 TensorBoard HParams 插件正确分组,通常你会为每次 hparam 运行使用单独的 writer
# 或者,如果使用同一个 writer,确保 metric_dict 中的键对于不同的运行是唯一的,
# 或者 add_hparams 会在内部处理。
# 较新版本的 TensorBoard/PyTorch 处理得更好。
writer.add_hparams(hparams_run1, metrics_run1, run_name="run1_sgd_lr0.01_bs32")
writer.add_hparams(hparams_run2, metrics_run2, run_name="run2_adam_lr0.001_bs64")
except Exception as e:
print(f"Could not log hparams (ensure PyTorch >= 1.3 and TensorBoard >= 2.2): {e}")
print("HParams logging might require specific TensorBoard setup or newer versions.")
提示: 对于 add_hparams,最可靠的方式是为每个超参数组合创建一个 SummaryWriter 实例,并写入到不同的子目录中,例如 runs/my_experiment/lr_0.01_bs_32。
8. 记录 Embeddings
用于可视化高维数据(如词嵌入、图像特征嵌入)在低维空间(通常是2D或3D,通过PCA或t-SNE)的投影。
writer.add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)
mat (torch.Tensor or numpy.ndarray): 形状为(N, D)的嵌入矩阵,其中N是数据点的数量,D是嵌入的维度。metadata (list of str, optional): 长度为N的列表,包含每个数据点的标签或元数据。如果metadata_header被设置,那么metadata也可以是一个列表的列表,每行对应一个数据点,每列对应metadata_header中的一个头部。label_img (torch.Tensor, optional): 形状为(N, C, H, W)的张量,包含每个数据点对应的图像。这些图像将在 TensorBoard 的投影仪中显示在数据点旁边。global_step (int, optional): 全局步骤。tag (str, optional): 嵌入的名称。metadata_header (list of str, optional): 如果metadata是表格形式,则此列表包含每列的标题。
print("Logging embeddings...")
# 假设我们有 50 个样本,每个样本是 20 维的特征向量
features_for_embedding = torch.randn(50, 20)
# 为每个样本生成标签 (例如,属于 5 个类别中的一个)
class_labels = [f'Class_{i // 10}' for i in range(50)]
# (可选) 为每个样本生成一个小的代表性图像 (这里用随机图像)
try:
dummy_images_for_embedding = torch.rand(50, 1, 10, 10) # 50 images, 1 channel, 10x10 pixels
writer.add_embedding(
mat=features_for_embedding,
metadata=class_labels,
label_img=dummy_images_for_embedding,
global_step=0,
tag='My_Feature_Embeddings'
)
except Exception as e:
print(f"Could not log embeddings (check tensor shapes, versions, and installation of 'tensorboard-plugin-profile'): {e}")
# Fallback without images if label_img causes issues
try:
writer.add_embedding(
mat=features_for_embedding,
metadata=class_labels,
global_step=0,
tag='My_Feature_Embeddings_no_img'
)
except Exception as e_no_img:
print(f"Could not log embeddings (even without images): {e_no_img}")
9. 记录 PR 曲线 (Precision-Recall Curve)
用于可视化二分类模型的精确率-召回率曲线。
writer.add_pr_curve(tag, labels, predictions, global_step=None, num_thresholds=127, weights=None, walltime=None)
tag (str): PR 曲线的标识符。labels (torch.Tensor or numpy.ndarray): 布尔型或 0/1 的真实标签。predictions (torch.Tensor or numpy.ndarray): 模型对每个样本的预测概率(或置信度),范围通常在 [0, 1]。global_step (int, optional): 全局步骤。num_thresholds (int, optional): 用于生成曲线的阈值数量。
print("Logging PR curve...")
# 模拟二分类任务的真实标签和预测概率
true_binary_labels = torch.randint(0, 2, (100,)) # 100 个 0 或 1 的真实标签
predicted_probabilities = torch.rand(100) # 100 个预测概率 (0 到 1)
try:
writer.add_pr_curve('Performance/PR_Curve', true_binary_labels, predicted_probabilities, 0)
except Exception as e:
# 可能需要安装特定版本的 protobuf 或修复版本冲突
print(f"Could not log PR curve: {e}. This sometimes requires `pip install protobuf==3.20.0` or similar fixes.")
最后,关闭 SummaryWriter
完成所有记录后,或者在程序退出前,确保关闭 writer。这会确保所有挂起的数据都被写入磁盘。
writer.close()
print("\nAll data logged (or attempted). Writer closed.")
1.3.3 TensorBoard 工作流与实时监控
理解 TensorBoard 的关键在于,它是一个独立的、基于 Web 的可视化工具,与你的 Python 训练脚本通过日志文件进行解耦。
核心工作流程 (Core Workflow)
整个过程分为三个独立但相互关联的步骤:
-
在 Python 脚本中记录 (Record in Python)
- 做什么: 在你的训练代码中,使用
SummaryWriter将需要监控的指标(如loss,accuracy)在每个训练步骤(epoch 或 batch)中写入到指定的日志目录(如runs/)。 - 关键代码:
writer.add_scalar('tag', value, step)
- 做什么: 在你的训练代码中,使用
-
在终端中启动服务 (Launch Service in Terminal)
- 做什么: 打开一个独立的终端窗口,运行
tensorboard命令,并指向你的日志目录。这将启动一个本地 Web 服务器。 - 关键命令:
# 确保你的终端位于能看到 runs 目录的位置 tensorboard --logdir=runs
- 做什么: 打开一个独立的终端窗口,运行
-
在浏览器中查看 (View in Browser)
- 做什么: 复制终端中显示的 URL (通常是
http://localhost:6006),在浏览器中打开它,即可看到可视化的图表。
- 做什么: 复制终端中显示的 URL (通常是
如何实现“边训练边查看” (Live Monitoring)
TensorBoard 最强大的功能之一就是实时监控。这是通过并行处理实现的:
-
终端 1: 运行训练脚本
python your_training_script.py这个脚本开始运行,并持续地向
runs/目录下的日志文件中追加新的数据点。 -
终端 2: 运行 TensorBoard 服务
tensorboard --logdir=runs这个服务在后台持续运行,它会定时检查日志文件是否有更新。
-
浏览器: 刷新查看
- 你可以在模型训练的任何时候打开或刷新浏览器中的 TensorBoard 页面。
- 你不需要关闭或重启任何东西。 每当你想查看最新进展时,只需点击 TensorBoard 页面右上角的刷新按钮。
- TensorBoard 会读取最新的日志数据,并将新产生的点绘制到图表上。你会眼看着损失曲线一点点地向右下方延伸,就像在看一场体育比赛的实时比分更新一样。
数据的动态获取 (How Data is Acquired Dynamically)
你可能会问,add_scalar() 中的数值是从哪里来的?它们并非手动输入,而是从训练循环中动态捕获的。
让我们再看一下这段核心代码:
# ... 在训练循环内部 ...
for epoch in range(num_epochs):
# 1. 模型计算,得到当前轮次的预测和损失
y_predicted = model(X)
loss = criterion(y_predicted, y)
# 2. 将当前轮次的动态值,传递给 writer
# - loss.item(): 从 PyTorch 张量中提取出当前的损失值 (一个浮点数)
# - epoch: 当前的训练轮数 (一个整数)
writer.add_scalar('Training/Loss', loss.item(), epoch)
writer.add_scalar('Parameters/Weight', model.weight.item(), epoch)
# ... 继续训练 ...
这里的关键机制是:
- 动态捕获 (Dynamic Capture):
loss和model.weight的值在每次迭代中都会因为模型的优化而改变。代码捕获的是当前这一步的瞬时值。 - 自动记录 (Automatic Recording):
writer.add_scalar()函数像一个忠实的记录员,将你提供的瞬时值和对应的步骤(epoch)打包成一个数据点,并存入日志。 - 迭代累积 (Iterative Accumulation): 随着
for循环的推进,成百上千个这样的数据点被连续记录下来,最终汇集成你在 TensorBoard 中看到的平滑曲线。
要点回顾
for n_iter in range(100): loss = 0.99**n_iter ...这类代码只是用于演示的模拟。- 在实际应用中,
n_iter是你的epoch或batch计数器,而loss,accuracy等数值是你模型在当前训练步骤真实计算出来的结果。 - 你只需将
writer.add_scalar()嵌入到训练循环中,就能实现对模型状态的全自动、实时监控。
1.4 Transforms
torchvision.transforms 是一个包含常见图像转换操作的模块,这些操作对于数据预处理和数据增强至关重要。
1.4.1 介绍 (Introduction)
为什么需要 Transforms?
-
数据预处理 (Preprocessing): 神经网络模型通常要求输入数据具有特定的格式。例如:
- 类型转换: 原始图像数据(如 PIL.Image 对象或 NumPy 数组)必须转换为
torch.Tensor。 - 尺寸统一: 一个批次内的所有图像通常需要有相同的尺寸。
- 归一化 (Normalization): 将像素值调整到特定范围和分布,这有助于模型更快、更稳定地收敛。
- 类型转换: 原始图像数据(如 PIL.Image 对象或 NumPy 数组)必须转换为
-
数据增强 (Data Augmentation):
- 目的: 通过对训练图像进行随机的、微小的改动(如旋转、翻转、裁剪、颜色抖动等),人为地增加训练数据的多样性。
- 好处: 这相当于免费扩充了训练集,可以有效减少模型过拟合,提高模型的泛化能力。
- 注意: 数据增强通常只在训练集上使用,而不在验证集和测试集上使用,以保证评估标准的一致性。
1.4.2 Transforms 内核源码解析 (Source Code Deep Dive)
要理解 transforms 的内核,最关键的一点是:torchvision.transforms 的设计采用了类包装器 + 函数式后端的模式。
- 类包装器 (Class Wrappers): 我们通常使用的
transforms.ToTensor,transforms.Resize等是面向用户的类。它们的主要职责是存储配置参数(通过__init__)并提供一个简单的调用接口(通过__call__)。 - 函数式后端 (Functional Backend): 真正的图像处理逻辑位于
torchvision.transforms.functional模块中(通常我们将其简写为F)。这个模块里的函数是无状态的,它们接收图像和所有必要的参数,并返回处理后的图像。
这个设计的核心思想是:将“配置”与“执行”分离。
让我们通过剖析几个关键 transform 的源码来彻底理解这一点。
深度解析 1: transforms.ToTensor
这是最基础也最重要的 transform。
第 1 步: 查看类包装器 transforms.ToTensor 的源码
# (这是 torchvision/transforms/transforms.py 中 ToTensor 类的简化源码)
import torchvision.transforms.functional as F
class ToTensor:
"""Convert a PIL Image or numpy.ndarray to tensor."""
def __init__(self):
# 这个 transform 是无状态的,不需要任何配置,所以 init 是空的。
pass
def __call__(self, pic):
"""
Args:
pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
Returns:
Tensor: Converted image.
"""
# __call__ 方法的核心就是调用 functional 后端的 to_tensor 函数
return F.to_tensor(pic)
def __repr__(self):
# 这是 print(transforms.ToTensor()) 时显示的字符串
return self.__class__.__name__ + '()'
源码分析:
ToTensor类本身非常简单,它几乎不做任何工作。- 它的
__call__方法只是一个“传球手”,把接到的图像pic直接传给了F.to_tensor函数。 - 真正的“内核”是
F.to_tensor。
第 2 步: 剖析内核函数 F.to_tensor
# (这是 torchvision/transforms/functional.py 中 to_tensor 函数的简化源码)
import torch
import numpy as np
from PIL import Image
def to_tensor(pic):
"""Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
"""
# 1. 输入类型检查
if not isinstance(pic, (Image.Image, np.ndarray)):
raise TypeError(f'pic should be PIL Image or ndarray. Got {type(pic)}')
# 2. 如果是 PIL Image,先转为 numpy.ndarray
if isinstance(pic, Image.Image):
# 如果是 'I' (32位整型), 'F' (32位浮点型) 等特殊模式,直接转换
if pic.mode in ('I', 'F'):
# ... 省略特殊模式处理 ...
pass
# 将 PIL Image 对象转换为 numpy 数组
np_img = np.array(pic, dtype=np.uint8, copy=True)
else: # 如果已经是 numpy.ndarray
np_img = pic
# --- 到这里,我们确保输入已经是一个 numpy 数组 (np_img) ---
# 3. 将 numpy 数组转换为 PyTorch Tensor
# 注意:此时的维度还是 HWC (Height, Width, Channel)
tensor = torch.from_numpy(np_img)
# 4. 核心步骤:维度重排 (HWC -> CHW)
# .permute(2, 0, 1) 的意思是:
# - 把原来的第2个维度(C)放到新张量的第0个位置
# - 把原来的第0个维度(H)放到新张量的第1个位置
# - 把原来的第1个维度(W)放到新张量的第2个位置
if tensor.ndim == 3: # 如果是彩色图像 (H, W, C)
tensor = tensor.permute(2, 0, 1).contiguous()
elif tensor.ndim == 2: # 如果是灰度图像 (H, W)
# 增加一个通道维度,变为 (1, H, W)
tensor = tensor.unsqueeze(0).contiguous()
# 5. 核心步骤:像素值缩放 (从 [0, 255] 缩放到 [0.0, 1.0])
# 检查张量是否已经是浮点型,如果不是,则进行转换和缩放
if not tensor.is_floating_point():
return tensor.float().div(255.0)
else:
# 如果已经是浮点型,则假定它已经在 [0.0, 1.0] 范围内,直接返回
return tensor
内核总结:
F.to_tensor 这个“内核”函数,精确地完成了三件大事:
- 统一类型: 将所有输入(PIL Image 或 NumPy Array)统一转换成
torch.Tensor。 - 维度重排: 将
(H, W, C)的数据布局调整为 PyTorch 卷积层所期望的(C, H, W)。 - 数值缩放: 将
[0, 255]的整数像素值标准化为[0.0, 1.0]的浮点数。
深度解析 2: transforms.Normalize
这个 transform 演示了“有状态”的类如何与函数式后端协作。
第 1 步: 查看类包装器 transforms.Normalize
# (torchvision/transforms/transforms.py 中 Normalize 类的简化源码)
class Normalize:
def __init__(self, mean, std, inplace=False):
# 1. __init__: 存储配置参数 (mean 和 std)
self.mean = mean
self.std = std
self.inplace = inplace
def __call__(self, tensor):
"""
Args:
tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
"""
# 2. __call__: 调用 functional 后端,并传入存储的配置
return F.normalize(tensor, self.mean, self.std, self.inplace)
源码分析:
Normalize类在__init__中接收并保存了mean和std这两个重要的配置参数。- 在
__call__中,它将待处理的tensor和自己保存的self.mean,self.std一起传递给内核函数F.normalize。
第 2 步: 剖析内核函数 F.normalize
# (torchvision/transforms/functional.py 中 normalize 函数的简化源码)
def normalize(tensor, mean, std, inplace=False):
# 1. 输入类型检查
if not isinstance(tensor, torch.Tensor):
raise TypeError('tensor is not a torch Tensor.')
# 2. 如果不是原地操作(inplace=False),先复制一份,避免修改原始张量
if not inplace:
tensor = tensor.clone()
# 3. 将 mean 和 std 转换为与 tensor 维度匹配的张量
# 这是为了利用 PyTorch 的广播机制 (broadcasting)
# 例如,mean=[0.5, 0.5, 0.5] -> tensor([[[0.5]], [[0.5]], [[0.5]]])
# 这样它就可以和 (C, H, W) 的图像张量进行逐元素的减法和除法
dtype = tensor.dtype
mean = torch.as_tensor(mean, dtype=dtype, device=tensor.device)
std = torch.as_tensor(std, dtype=dtype, device=tensor.device)
# .view(-1, 1, 1) 是关键,它将 (C,) 的向量变为 (C, 1, 1) 的张量
mean = mean.view(-1, 1, 1)
std = std.view(-1, 1, 1)
# 4. 执行归一化数学运算: tensor = (tensor - mean) / std
tensor.sub_(mean).div_(std) # sub_ 和 div_ 是原地操作(in-place)
return tensor
内核总结:
F.normalize 的核心是利用 PyTorch 的张量运算和广播机制高效地完成数学计算。它通过 view 方法巧妙地解决了 mean/std 向量和图像张量之间的维度匹配问题。
深度解析 3: transforms.Compose
Compose 是一个特殊的 transform,它本身不处理图像,而是将其他 transform 串联起来。它的实现非常优雅。
# (torchvision/transforms/transforms.py 中 Compose 类的简化源码)
class Compose:
def __init__(self, transforms):
# __init__: 接收一个 transform 实例的列表并保存
self.transforms = transforms
def __call__(self, img):
# __call__: 遍历列表,将上一个 transform 的输出作为下一个的输入
for t in self.transforms:
img = t(img)
return img
源码分析:
Compose 的实现简洁明了。它的 __call__ 方法就是一个简单的 for 循环,完美地实现了“管道式”的处理流程。
结论
通过深入源码,我们可以清晰地看到 torchvision.transforms 的设计哲学:
- 职责分离: 用户交互的类负责存储配置,而核心逻辑的函数负责执行计算。
- 原子操作:
functional模块中的函数都是原子化的、无状态的,易于测试和复用。 - 优雅组合:
Compose提供了一个简单而强大的机制,可以将任意原子操作组合成复杂的处理流水线。
1.4.3 常用 Transforms 函数及用法
torchvision.transforms 提供了丰富的预定义转换。下面是一些最常用的:
1. 尺寸变换 (Sizing)
transforms.Resize(size): 将输入图像的尺寸调整为size。如果size是一个整数,则图像的短边会被缩放到该尺寸,长边按比例缩放。如果size是一个元组(h, w),则图像会被直接调整到该高和宽。transforms.CenterCrop(size): 以图像中心为原点,裁剪出size大小的区域。transforms.RandomCrop(size, padding=None, ...): 从图像的随机位置裁剪出size大小的区域。常用于数据增强。
2. 翻转与旋转 (Flipping & Rotation)
transforms.RandomHorizontalFlip(p=0.5): 以概率p(默认为 50%) 水平翻转图像。transforms.RandomVerticalFlip(p=0.5): 以概率p垂直翻转图像。transforms.RandomRotation(degrees, ...): 在(-degrees, +degrees)范围内随机旋转图像。
3. 类型转换与归一化 (Type Conversion & Normalization)
transforms.ToTensor(): 核心中的核心。它执行三个操作:- 将输入的
PIL.Image或numpy.ndarray转换为torch.Tensor。 - 将维度顺序从 HWC (Height, Width, Channel) 调整为 CHW (Channel, Height, Width)。
- 将像素值从
[0, 255]的整数范围,按比例缩放到[0.0, 1.0]的浮点数范围。
- 将输入的
transforms.Normalize(mean, std): 对一个 CHW 格式的 Tensor 进行归一化。公式为output[channel] = (input[channel] - mean[channel]) / std[channel]。mean和std都是对应通道数的序列(如 3 通道图像的[r_mean, g_mean, b_mean])。- 常用值 (ImageNet):
mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]
- 常用值 (ImageNet):
4. 组合多个 Transforms
在实际应用中,我们需要将多个操作串联起来。transforms.Compose 就是用来做这件事的。
transforms.Compose([transform_1, transform_2, ...]): 它接收一个由 transform 实例组成的列表。当对图像应用这个Compose对象时,它会按照列表中的顺序,依次执行每一个 transform。
5. 在 Dataset 中使用
这是 transforms 最典型的应用场景:将定义好的转换流程传递给 Dataset。
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
# 1. 定义一个用于训练的转换流程 (包含数据增强)
train_transforms = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 2. 定义一个用于验证/测试的转换流程 (无数据增强)
test_transforms = transforms.Compose([
transforms.Resize(224), # 或者 Resize(256) + CenterCrop(224)
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 3. 将 transform 传递给 Dataset 实例
# (这里使用一个伪代码的 MyImageDataset)
class MyImageDataset(Dataset):
def __init__(self, file_list, transform=None):
self.files = file_list
self.transform = transform
def __getitem__(self, index):
# 伪代码: 加载图像
image = Image.open(self.files[index]).convert("RGB")
if self.transform:
image = self.transform(image) # <-- 在这里应用
return image, 0 # 返回图像和标签
def __len__(self):
return len(self.files)
# 实例化 Dataset
# train_dataset = MyImageDataset(train_files, transform=train_transforms)
# test_dataset = MyImageDataset(test_files, transform=test_transforms)
# 4. 创建 DataLoader
# train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
这样,DataLoader 在每次从 Dataset 中取出一个样本时,都会自动地、高效地应用你所定义的 transforms 流程。