CNN 中的通道 (Channels in CNN)
CNN 中的“通道”是一个从具体到抽象演变的核心概念。它始于我们熟悉的图像颜色通道,但在网络内部,其含义发生了根本性的变化,成为了 CNN 学习和识别物体的基石。
1. 区别与联系:颜色通道 vs. 特征通道
相同点:数据结构
无论是图像的颜色通道,还是 CNN 内部的特征通道,它们在数据结构上是完全一致的。它们都是一个三维张量 (C, H, W) 在深度维度 (C) 上的“切片”。
C: 通道数 (Channels)H: 高度 (Height)W: 宽度 (Width)
这个统一的数据结构使得卷积操作可以在网络的不同层级上以相同的方式进行。
不同点:物理意义
这是两者最本质的区别:
- 颜色通道 (输入层): 代表了物理世界的光学属性。例如,一个 3 通道的输入代表了图像在每个像素点的红、绿、蓝三种光的强度。它的意义是具体、可解释的。
- 特征通道 (隐藏层): 代表了模型从图像中学到的抽象特征。它不再对应任何颜色,而是对应一个“特征检测器”。一个通道可能对“竖直边缘”敏感,另一个可能对“猫的眼睛”敏感。它的意义是抽象、由学习得到的。
2. 核心机制:CNN 如何处理和创造通道
CNN 通过卷积操作,将输入的通道信息进行融合 (Fuse),并创造出新的特征通道。这个过程并不是简单的“叠加”,而是一个加权求和的融合过程。
卷积核的结构
一个卷积层想要处理多少个输入通道,它的卷积核就必须有多深。
- 输入: 一张
(3, H, W)的 RGB 图像。 - 卷积核: 它的深度必须也为 3。如果核的尺寸是
3x3,那么它的完整形状就是(3, 3, 3)。Kernel_Channel_0: 专门与输入图像的红色通道进行计算。Kernel_Channel_1: 专门与输入图像的绿色通道进行计算。Kernel_Channel_2: 专门与输入图像的蓝色通道进行计算。
卷积操作详解 (产生一个输出通道)
-
对齐: 将
(3, 3, 3)的卷积核对准输入图像(3, H, W)的某个3x3区域。 -
分通道计算: 对每一个通道,进行逐元素相乘再求和。
- 将核的红色通道与图像的红色通道对应区域计算,得到一个数值
Sum_R。 - 将核的绿色通道与图像的绿色通道对应区域计算,得到
Sum_G。 - 将核的蓝色通道与图像的蓝色通道对应区域计算,得到
Sum_B。
- 将核的红色通道与图像的红色通道对应区域计算,得到一个数值
-
融合: 将所有通道计算出的结果相加,并加上一个偏置项(bias),形成最终的单一输出值。
Final_Result = Sum_R + Sum_G + Sum_B + bias
-
生成特征图: 这个
Final_Result就是输出特征图上的一个像素点。卷积核在整个输入图像上滑动,重复上述步骤,最终生成一个完整的、单通道的输出特征图。
可视化过程:
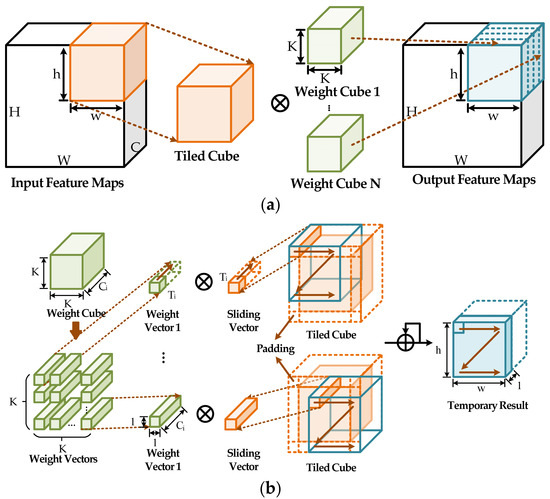
- 左边的蓝色立方体是输入图像(3通道)。
- 中间滑动的半透明立方体是卷积核(3通道)。
- 右边的绿色矩阵是生成的单通道输出特征图。
可以看到,每次计算输出图的一个像素时,输入的所有通道都参与了运算,它们的信息被融合成一个值。
3. 如何产生多个输出通道?
很简单:一个卷积核(Filter)产生一个输出通道(Feature Map)。
如果希望一个卷积层产生 16 个输出通道,那么就需要 16 个独立的卷积核!
- 每一个卷积核的形状都是
(3, 3, 3)(深度与输入匹配)。 - 第一个卷积核与输入的 3 个通道计算,产生第 1 个输出特征图。这个核可能学习去检测“水平线”。
- 第二个卷积核(权重完全不同)与输入的 3 个通道计算,产生第 2 个输出特征图。这个核可能学习去检测“绿色斑点”。
- ...
- 第十六个卷积核产生第 16 个输出特征图。
最后,这 16 个单通道的输出特征图在深度维度上堆叠起来,形成一个 (16, H', W') 的输出张量,作为下一层的输入。
4. 总结
- 起点相同,意义不同: CNN 通道始于物理的颜色通道,但迅速转变为抽象的特征通道。
- 不是叠加,是融合: 输入通道的信息在卷积时被加权求和,融合成一个值,而不是简单地堆叠。
- 一个核,一个输出通道: 卷积核的深度匹配输入通道数,但它只产生一个输出特征图。
- 多核,多输出通道: 想要得到
N个输出特征通道,就需要N个独立的卷积核。 - 学习的核心: 在训练时,模型学习的就是这些卷积核里的权重值。这使得每个核都能专门化地去检测一种有用的模式(从简单的边缘、颜色,到复杂的形状、物体部件),从而实现强大的图像识别能力。